Программист-прагматик. Путь от подмастерья к мастеру, стр. 45
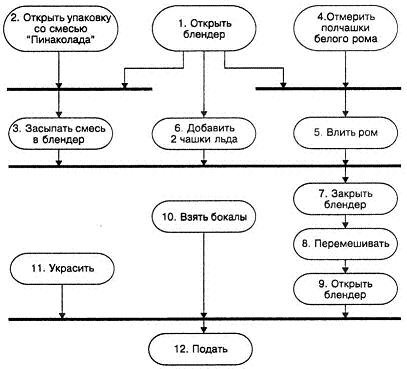
Это может открыть вам глаза на реально существующие зависимости. В этом случае задачи высшего уровня приоритета (1, 2, 4, 10 и 11) могут выполняться параллельно, как бы авансом. Задачи 3, 5 и 6 могут выполняться параллельно, но позже.
Если бы вы участвовали в конкурсе по приготовлению коктейлей «Пинаколада», эти оптимальные решения выгодно отличали бы вас от всех остальных.
Рис. 5.2. Диаграмма на языке UML: приготовление коктейля "Пинаколада"
Архитектура
Несколько лет назад мы написали систему оперативной обработки транзакций (OLAP – on-line transaction processing). В простейшем варианте все, что должна была сделать система, – это принять запрос и обработать транзакцию в сравнении с БД. Но мы написали трехзвенное, многопроцессорное распределенное приложение: каждый компонент представлял собой независимую единицу, которая выполнялась параллельно со всеми другими компонентами. Хотя при этом возникает впечатление большой работы, это не так: при написании этого приложения мы использовали преимущество временной несвязанности. Рассмотрим этот проект более подробно.
Система принимает запросы от большого числа каналов передачи данных и обрабатывает транзакции в рамках БД.
Проект налагает следующие ограничения:
• Операции с БД занимают сравнительно большое время.
• При каждой транзакции мы не должны блокировать коммуникационные службы в момент обработки транзакции БД.
• Производительность базы ухудшается за счет слишком большого числа параллельных сеансов.
• Множественные транзакции осуществляются параллельно на каждой линии передачи данных.
Решение, обеспечивающее наилучшую производительность и самый четкий интерфейс, выглядит подобно представленному на рисунке 5.3.
РИС. 5.3. Общая схема архитектуры системы оперативной обработки транзакций
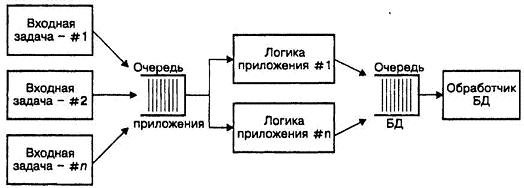
Каждый прямоугольник обозначает отдельный процесс; процессы связываются через очереди работ. Каждый входной процесс отслеживает состояние одного входного канала связи и осуществляет запросы к серверу приложения. Все запросы являются асинхронными: как только входной процесс осуществляет текущий запрос, он сразу же возвращается к отслеживанию канала на наличие трафика. Точно так же сервер приложения осуществляет запросы процесса БД [32] и уведомляется в момент завершения отдельной транзакции.
На этом примере также демонстрируется способ быстрого и грубого распределения нагрузки между множественными потребительскими процессами: это так называемая модель голодного потребителя.
В модели голодного потребителя центральный планировщик заменяется на несколько независимых задач потребителя и централизованную очередь работ. Каждая задача потребителя захватывает некий фрагмент очереди работ и продолжает заниматься своим делом – его обработкой. Как только задача заканчивает свою работу, она возвращается к очереди за новой порцией. В этом случае, если выполнение какой-либо задачи срывается, другие задачи могут "натянуть поводья" и каждый отдельный компонент может продолжаться в своем собственном темпе. Происходит временная несвязанность одного компонента с другими.
Подсказка 40: Проектируйте, используя службы
На самом деле, вместо компонентов мы создали службы – независимые, параллельные объекты, скрытые за четко определенными, непротиворечивыми интерфейсами.
Проектирование с использованием принципа параллелизма
Поскольку Java все чаще принимается в качестве платформы, многие разработчики перешли к многопоточному программированию. Но программирование с использованием потоков налагает на конструкцию некоторые ограничения – и это хорошо. Эти ограничения настолько полезны, что нам хотелось бы пребывать под их благодатным покровом, когда бы мы ни занимались написанием программ. Это поможет нам делать нашу программу несвязанной и бороться с так называемым "программированием в расчете на стечение обстоятельств" (см. ниже одноименный раздел).
При работе с линейной программой легко сделать предположения, которые в конечном итоге приведут к небрежно написанным программам. Но параллелизм заставляет задумываться о происходящем несколько глубже – вы больше не находитесь в безвоздушном пространстве. Поскольку многие события могут теперь происходить "в одно и то же время", вы можете внезапно столкнуться с зависимостями, основанными на факторе времени. Прежде всего необходимо защитить любые глобальные или статические переменные от параллельного доступа. Теперь можно задать самому себе вопрос, зачем нужна глобальная переменная на первом месте. Кроме того, необходимо убедиться в том, что вы предоставляете непротиворечивую информацию о состоянии независимо от порядка вызовов. Например, в какой момент допускается опрашивание состояния вашего объекта? Если ваш объект находится в недопустимом состоянии в период между определенными вызовами, то вы, вероятно, полагаетесь на стечение обстоятельств – никто не вызовет ваш объект в этот момент времени.
Предположим, что есть подсистема работы с окнами, в которой интерфейсные элементы вначале создаются, а затем отображаются на дисплее. Вам не разрешается задавать состояние в элементе, пока он не отобразится. В зависимости от заданных параметров программы вы можете полагаться на то условие, что ни один другой объект не может воспользоваться созданным элементом, пока вы не выведете его на дисплей.
Но в параллельной системе это может и не выполняться. При вызове объекты всегда обязаны находиться в допустимом состоянии, а они могут вызываться в самое неподходящее время. Вы обязаны убедиться, что объект находится в допустимом состоянии в любой момент, когда потенциально он может быть вызван. Зачастую эта проблема возникает с классами, которые определяют отдельные программы конструктора и инициализации (где конструктор не оставляет объект в инициализированном состоянии). Используя инварианты класса, обсуждаемые в разделе "Проектирование по контракту", вы сможете избежать этой ловушки.
Размышления о параллелизме и зависимостях, упорядоченных во времени, могут заставить вас проектировать более четкие интерфейсы. Рассмотрим библиотечную подпрограмму на языке С под названием strtok, которая расщепляет строку на лексемы.
Конструкция strtok не является поточно-ориентированной [33], но это не самое плохое, рассмотрим временную зависимость. Первый раз вы обязаны вызвать подпрограмму Strtok с переменной, которую вы хотите проанализировать, а во всех последующих вызовах использовать NULL вместо этой переменной. Если переменная принимает значение, отличное от NULL, программа повторно производит разбор содержимого буфера. Не принимая во внимание потоки, предположим, что вы собираетесь использовать Strtok для одновременного синтаксического анализа двух отдельных строк:
char buf1[BUFSIZ];
char buf2[BUFSIZ];
char *p, *q;
strcpy(bufl, "это тестовая программа");
strcpy(buf2, "которая не будет работать");
р = strtck(buf1," ");
q = strtok(buf2," ");
while (p && q) {
printf("%s %s\n", p, q);
p = strtok(NULL, " ");
q = strtok(NULL, " ");
}
Представленная программа работать не будет: существует неявное состояние, сохраняющееся в strtok между запросами. Вам придется использовать Strtok одновременно только с одним буфером.
Конструкция синтаксического анализатора строк на языке Java будет отличаться от указанной выше. Она должна быть поточно-ориентированной и представлять непротиворечивое состояние.
32
Несмотря на то, что база данных показана как единое целое, это не так. Программное обеспечение баз данных разделено на несколько процессов и клиентских потоков, но их обработка производится внутренними программами БД и не является частью примера, приведенного в книге.
33
Она использует статические данные для сохранения текущей позиции в буфере. Статические данные не защищены от параллельного доступа, поэтому они не являются поточно-ориентированными. Помимо этого, программа strtok затирает первый передаваемый параметр, что может привести к весьма неприятным сюрпризам.)